- 发布于
Model Compression
AI 摘要
- 作者

- 姓名
- Corner430
- 社交账号
- Model Compression
- Network Pruning
- Knowledge Distillation
- Parameter Quantization
- Arichitecture Design
- Dynamic Network
1. Network Pruning
只要它是 NN 就 OK
Network can be pruned
- Networks are typecally over-parameterized(there is significant redundant weight or neurons)
- Importance of a weight
- Importance of a neuron: the number of times it wasn’t zero on a given data set…
- After pruning, the accuracy will drop(hopefully not too much)
- Fine-tuning on training data for recover
- Don’t prune too much at once, or the network won’t recover
要反复进行剪枝和微调,直到满足要求为止
- How about simply train a smaller network?
- It is widely known that smaller networks is more difficult to learn successfully.
- Larger network is easier to optimize?
这里有两篇观点完全相反的 *paper: The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks and Rethinking the Value of Network Pruning*,进行探讨小模型是否可以直接 train
Network Pruning-Practical Issue
Weight pruning
- *The network architecture becomes irregular. Hard to implement, hard to speedup(GPU不好加速)…*.(为解决这个问题,一般而言不会直接把 weight 剪掉,而是将其设置为 0,这样可以保持网络结构的完整性)
- 详细可参考 Learning Structured Sparsity in Deep Neural Networks,扔掉 95% 的 weight 都没关系
Neuron pruning
- The network architecture is regular. Easy to implement, easy to speedup(GPU好加速)…
- A three-stage pipeline to reduce the storage requirement of neural nets
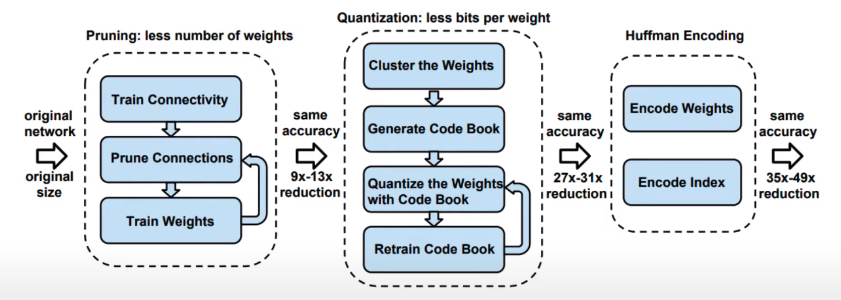
- Showed a 35x decrease in size of AlexNet from 240MB to 6.9MB with no loss in accuracy
- Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding
2. Knowledge Distillation
目前限定在分类问题
3. Parameter Quantization
- 1. Using less bits to represent a value
- 2. Weight clustering
- K-means clustering
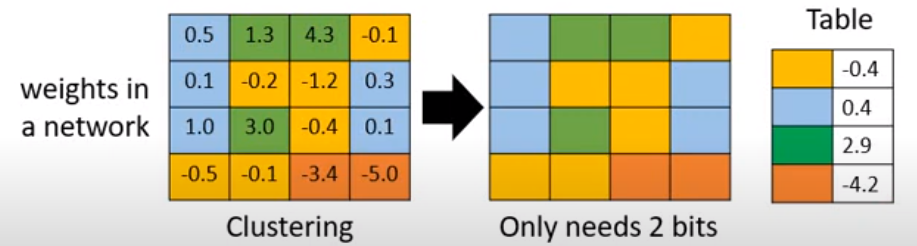
- 3. Represent frequent clusters by less bits, represent rare clusters by more bits
- e.g. Huffman encoding
BinaryConnect 有时候效果反而更好,因为这本质上属于一种正则
4. Arichitecture Design
- 对于 FC, 可以将其分解为两个 FC,这样可以减少参数量。本质上还是和矩阵分解有些关系
- 对于 CNN
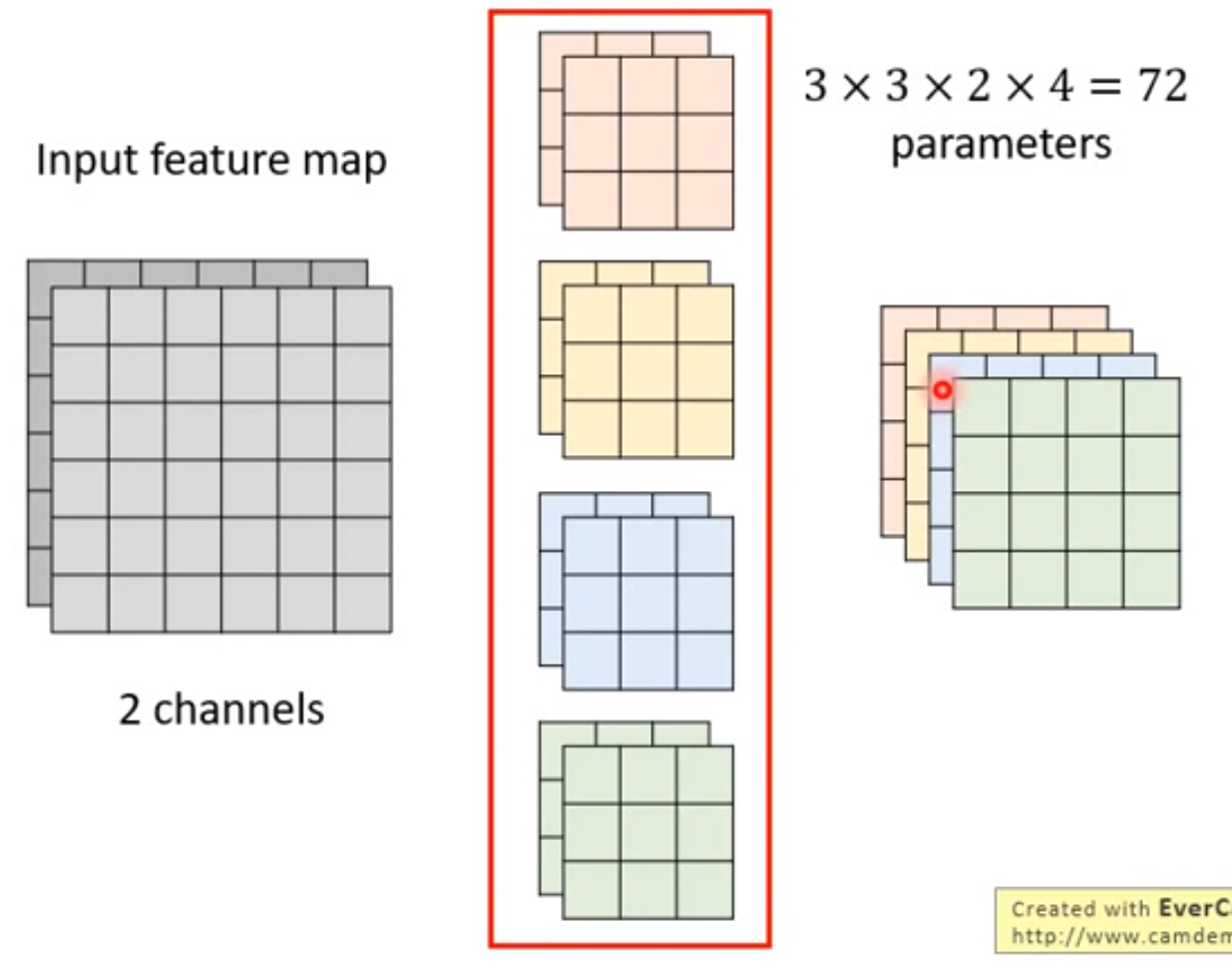
Depthwise Separable Convolution 参数对比,*参数量可以降低 kernel_size kernel_size,存在着参数复用*
Learn more …
- SqueezeNet
- SqueezeDet: Fully Convolutional Network for fast object detection
- MobileNet
- ShuffleNet
- Xception
- SEP-Net: Transforming k × k convolution into binary patterns for reducing model size
5. Dynamic Network
Can network adjust the computation power it need?
Possible solutions:
- 1. Train multiple classifiers
- 2. Classifier at the intermedia layer
参考 Multi-Scale Dense Networks for Resource Efficient Image Classification
- 使用训练并剪枝之后的网络权重,去初始化一个更小的网络
- weight pruning 置 0,保存非零权重,利用蒸馏的方法,将剪枝后的网络的知识蒸馏到更小的网络中
- 家教 + 教授
- 万能的 NiN
Further Studies
- Can we find winning tickets early on in training?(You et al, 2020)
- Do wining tickets generalize across datasets and optimizer?(Morcos et al, 2019)
- Can this hypothesis hold in other domains like text processing/NLP?(Yu et al, 2019)
Reading
- Robert T. Lange, Lottery Ticket Hypothesis: A Survey, 2020
- Cheng et al., A Survey of Model Compression and Acceleration for Deep Neural Networks, 2017
Song Han, Lecture 10 - Knowledge Distillation | MIT 6.S965
版权声明
- 作者: Corner430
- 标题: Model Compression
- 链接: https://corner430-ai-blog.vercel.app/blog/Model-Compression
- 许可协议: CC BY-NC-SA 4.0
除非另有说明,本文内容采用 CC BY-NC-SA 4.0 许可协议。转载请注明出处。